Appendice E. RAID (Redundant Array of Independent Disks)
Cos'č il RAID?
L'idea di base dietro al RAID č di combinare piů dischi di modeste dimensioni e di costo ridotto in un array che supera in prestazioni quelle di un unico, grande e costoso disco. Questo array di dischi viene visto come un unico dispositivo dal computer.
La tecnologia RAID offre un metodo per suddividere le informazioni su vari dischi, usando tecniche come disk striping (RAID Level 0) e disk mirroring (RAID level 1) per aggiungere ridondanza ai dati e per migliorare la velocutŕ di lettura e di scrittura.
Il concetto di base della tecnologia RAID č che i dati possono venir distribuiti tra i dischi dell'array in maniera consistente. Per fare questo, i dati devono venir prima spezzati in "chunk" (spesso di 32k o 64k di grandezza, anche se altre dimensioni possono venir usate). Ogni chunk viene cosě scritto sui dischi a turno. Quando i dati vengono letti, il processo avviene al contrario, dando l'illusione che piů dischi siano combinati in una unica unitŕ.
Chi dovrebbe usare i RAID?
Coloro che hanno bisogno di gestire grandi quantitŕ di dati e di avere un sistema robusto ai guasti hardware. Le principali ragioni per usare la tecnologia RAID sono:
aumento della velocitŕ
aumento della capacita di archiviazione
grande efficienza nel recupero in seguito ad un crash del sistema
RAID: Hardware contro Software
Esistono due possibili approcci al RAID: RAID Hardware e RAID Software.
RAID Hardware
Le soluzioni hardware gestiscono il sottosistema RAID indipendentemente dall'host e presentano all'host un singolo disco per array.
Un esempio di RAID hardware potrebbe essere quello connesso a un controller SCSI che presenta al sistema un singolo disco SCSI. Un sistema RAID č gestito dal controller RAID. Tutto il sottosistema č connesso ad un calcolatore tramite un normale controller SCSI ed appare come un singolo disco.
Esistono anche controller RAID nella forma di schede che agiscono come un controller e gestiscono tutte le comunicazioni reali tra i dischi in modo autonomo. In questi casi, basta collegare i dischi ad un controller RAID cosě come fareste con un controller SCSI.
RAID Software
Il Software RAID implementa i vari livelli di RAID nel codice del kernel riguardante la gestione del disco (block device). Offre inoltre la soluzione in assoluto meno costosa: Non sono richiesti costosi controller dedicati o chassis hot-swap, [1] e il RAID software funziona sia con dischi IDE meno costosi sia con dischi SCSI. Con le CPU dell'ultima generazione, le prestazioni di un RAID software possono eccellere quelle di un RAID hardware.
Il driver MD nel kernel di Linux č un esempio di una soluzione RAID che č completamente indipendente dall'hardware. Le prestazioni di un array basato su software dipende sulle performance e sul carico della CPU.
Alcune caratteristiche del RAID
Questa č una breve lista di alcune caratteristiche offerte dal RAID software:
Processo di ricostruzione basato su thread
Configurazione completamente basata sul kernel
Portabilitŕ di array tra macchine Linux senza ricostruire l'array RAID.
Ricostruzione dell'array in background utilizzando risorse inutilizzate di sistema
Supporto per drive Hot-swappable
Riconoscimento automatico della CPU per avvantaggiarsi di alcune ottimizzazioni della CPU
Livelli e supporto lineare
Il RAID offre il supporto per i livelli 0, 1, 4, 5, e lineare. Questi tipi di RAID si comportano nel modo seguente:
Livello 0 -- Il RAID livello 0, spesso chiamato "striping," č una tecnica orientata alle prestazioni di mappatura dati "striped". Questo vuol dire che i dati scritti sull'array, vengono divisi in strisce e scritti sui dischi membri dell'array. Questo permette alte prestazioni di I/O ad un basso costo ma non fornisce ridondanza. La capacitŕ di memorizzazione dell'array č uguale alla capacitŕ totale dei dischi membri.
Livello 1 -- Il RAID livello 1, o "mirroring," č stato utilizzato piů a lungo rispetto ad altre forme di RAID. Il livello 1 fornisce ridondanza scrivendo dati identici su ogni disco membro dell'array, lasciando una copia "identica" su ciascun disco. Il mirroring rimane popolare a causa della sua semplicitŕ ed alto livello di disponibilitŕ di dati. Il livello 1 opera con due o piů dischi che possono utilizzare una modalitŕ di accesso parallelo per trasferimenti veloci di dati in lettura, ma piů comunemente opera in modo indipendente per provvedere alti valori di transazioni I/O. Il livello 1 fornisce un'alta affidabilitŕ e migliora le prestazioni per applicazioni intensive nella lettura dati ma ad un costo relativamente alto [2]. La capacitŕ dell'array č uguale alla capacitŕ di un disco membro dell'array stesso.
Livello 4 -- Il RAID livello 4 utilizza la paritŕ[3] concentrandola su un singolo disco per la protezione dei dati. Č piů orientato per le transazioni di I/O piuttosto che per pesanti trasferimenti di dati. Poiché il disco dedicato alla paritŕ rappresenta un non indifferente collo di bottiglia, il livello 4 č raramente utilizzato senza tecnologie aggiuntive come il write-back caching. Anche se il RAID di livello 4 č un'opzione in alcuni schemi di ripartizionamento RAID, non č un opzione permessa nell'installazione RAID di Red Hat Linux[4]. La capacitŕ dell'array č uguale alla capacitŕ dei dischi membri meno la capacitŕ di un disco.
Livello 5 -- Il tipo piů comune di RAID. Distribuendo la paritŕ tra alcuni o tutti i dischi membri, Il RAID livello 5 elimina il collo di bottiglia inerente al livello 4. L'unico collo di bottiglia č il processo di calcolo della paritŕ. Con le moderne CPU il RAID software non rappresenta un grosso collo di bottiglia. Come con il livello 4, i risultati sono prestazioni molto elevate, con le letture che sostanzialmente sono piů performanti delle scritture. Il livello 5 č spesso utilizzato con il write-back caching per ridurre l'asimmetria. La capacitŕ dell'array č uguale alla capacitŕ dei dischi membri meno la capacitŕ di un disco.
RAID lineare -- Il RAID lineare č un semplice raggruppamento di dischi in modo da creare un disco virtuale piů grande. Nel RAID lineare, i chunk sono disposti sequenzialmente da un disco membro fino al disco successivo solo quando il primo č completamente riempito. Questo raggruppamento non porta vantaggi in prestazioni, cosě come č poco probabile che alcuna operazione di I/O venga divisa tra i dischi membri. Il RAID lineare non offre ridondanza, e infatti l'affidabilitŕ diminuisce -- se uno dei drive viene meno, l'intero array non puň essere utilizzato. La capacitŕ č quella totale di tutti i dischi.
Creare Partizioni RAID
Il RAID č disponibile in entrambe le modalitŕ di installazione GUI e kickstart. Potrete utilizzare l'fdisk o il Disk Druid per creare la vostra configurazione RAID, ma queste istruzioni saranno focalizzate sull'utilizzo di Disk Druid per completare questa operazione.
Prima di creare un dispositivo RAID, dovete creare delle partizioni RAID utilizzando le seguenti istruzioni.
 | Suggerimento: Se utilizzate fdisk |
|---|---|
Se state utilizzando fdisk per creare una partizione RAID, dovete tener presente che invece di creare una partizione di tipo 83, che č Linux native, dovrete crearla di tipo fd (Linux RAID). |
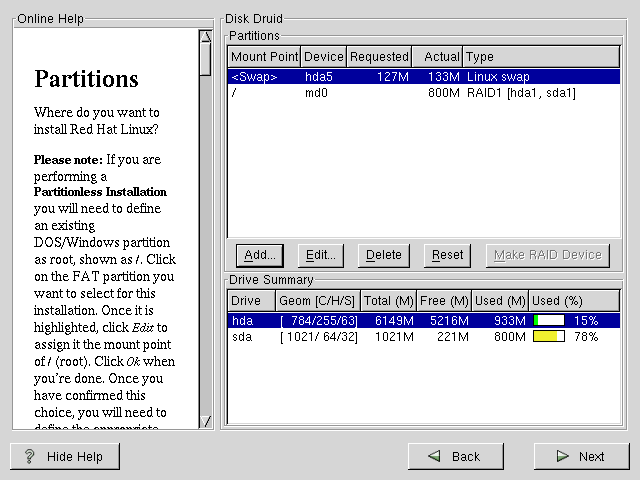
Create una partizione. In Disk Druid, dovrete scegliere Add per creare una nuova partizione (vedasi Figura E-1).
Non potete inserire un mount point (potrete farlo una volta creato il vostro device RAID).
Inserite la dimensione per la partizione.
Selezionate Grow to fill disk se volete che la partizione occupi tutto lo spazio libero disponibile su disco. In questo caso, la dimensione verrŕ espansa e diminuita a seconda delle modifiche fatte alle altre partizioni. Se selezionate piů di una partizione "growable", le partizioni competeranno per lo spazio disponibile su disco.
Inserite il tipo di partizione RAID.
Infine, per Allowable Drives, selezionate il disco dove verrŕ creato il RAID. Se avete dischi multipli, tutti i dischi verranno selezionati e dovrete deselezionare quei drive che non vorrete nell'array RAID.
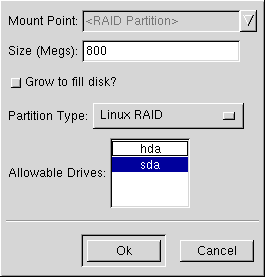
Continuate con questi passi in modo da creare le partizioni di cui avete bisogno per la vostra configurazione RAID.
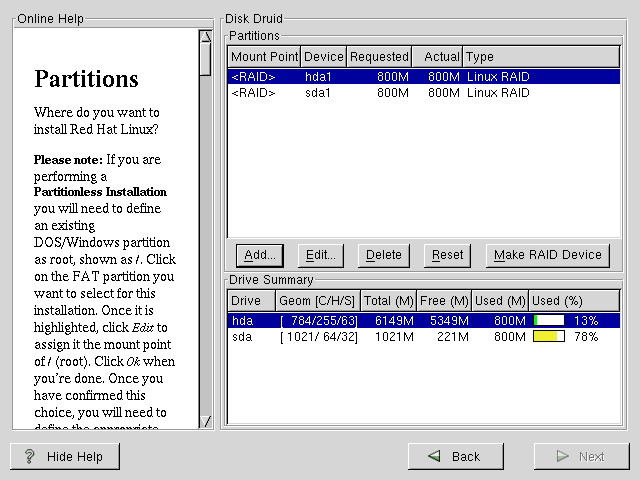
Una volta che tutte le vostre partizioni sono state create come RAID, selezionate il tasto Make RAID Device sullo schermo principale di Disk Druid (vedasi Figura E-2).
Successivamente, apparirŕ la Figura E-3 che vi permetterŕ di creare un dispositivo RAID.
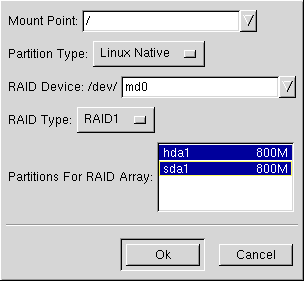
Prima di tutto, inserite un mount point.
In seguito, assicuratevi che il tipo di partizione sia selezionata come Linux Native (che sarŕ quella predefinita).
Scegliete il vostro dispositivo RAID. Dovreste scegliere md0 come primo device, md1 come secondo, e cosě via, a meno che non abbiate una ragione particolare per creare i device in maniera differente. I device RAID vanno da md0 a md7, ed ognuno puň essere scelto solo una volta.
Scegliete il tipo di RAID. Potete scegliere tra RAID 0, RAID 1, e RAID 5.

Nota Bene Se state creando una partizione RAID di /boot, dovete scegliere RAID livello 1. Se non ne state creando una, e state creando una partizione /, deve essere RAID livello 1.
Infine, selezionate quali partizioni andranno in questo array RAID (come in Figura E-4) e quindi premete il pulsante Next.
Da qui, potete continuare il processo di installazione. Fate riferimento al Official Red Hat Linux Installation Guide per maggiori istruzioni.